精品軟體與實用教程





SEO優化
SEO最佳化 GoogleSEO怎樣做?和百度SEO有多大差別?本質上差異不大,但有些細節差異。由於谷歌搜尋技術的領先,掌握Google SEO十分重要,前幾天一位國內某大型電商SEO部門的朋友問我一個很有趣的Google排名問題,一兩句話說不清楚,所以寫個帖子回答,也許對其它SEO也有幫助。
TDK優化
TDK為title,description,keywords三個的統稱。當然title是最有用的,是非常值得優化的;而keywords因為以前被seo人員過度使用,所以現在對這個進行優化對搜尋引擎是沒用的,這裡就不說了;description的描述會直接顯示在搜尋的介紹中,所以對使用者的判斷是否點擊還是非常有效的。
title優化
title的分隔符號一般有,,_,-等,其中_對百度比較友好,而-對Google比較友好,第四個為空格,英文站點可以使用,中文少用。title長度一般pc端大概30個中文,行動端20個,超過則會截斷為省略號。
因為業務關係,我們做的更多的是針對百度搜尋引擎的優化,所以這裡把百度搜尋引擎優化的建議分享下:
title格式:
- 首頁:
網站名稱或者網站名稱_提供服務介紹or產品介紹 - 頻道頁:
頻道名稱_網站名稱 - 文章頁:
文章title_頻道名稱_網站名稱
如果你的文章標題不是很長,還可以加入點關鍵字進去,如文章title_關鍵字_網站名稱
推薦做法:
- 每個網頁應該有一個獨一無二的標題,切忌所有的頁面都使用相同的預設標題
- 標題要主題明確,包含這個網頁中最重要的內容
- 簡明精練,不羅列與網頁內容不相關的訊息
- 使用者瀏覽通常是從左到右的,重要的內容應該放到title的前面的位置
- 使用用戶所熟知的語言描述。如果你有中、英文兩種網站名稱,盡量使用用戶熟知的那一種做為標題描述
description優化
description不是權值計算的參考因素,這個標籤存在與否不影響網頁權值,只會用做搜尋結果摘要的一個選擇目標。其長度pc端大概為78個中文,行動端為50個,超過則會截斷為省略號。
百度推薦做法為:
- 網站首頁、頻道頁、產品參數頁等沒有大段文字可以用做摘要的網頁最適合使用description
- 準確的描述網頁,不要堆砌關鍵字
- 為每個網頁建立不同的description,避免所有網頁都使用相同的描述
- 長度合理,不過長不過短
以下以百度推薦的兩個例子為對比,第一個沒有應用meta description,第二個應用了meta description,可以看出第一個結果的摘要對用戶基本上沒有參考價值,第二個結果的摘要更具可讀性,可以讓用戶更了解網站的內容。

頁面內容優化
使用html5結構
如果條件允許(如行動端,相容ie9+,如果ie8+就針對ie8引入html5.js吧),是時候開始考慮使用html5語意化標籤。如header,footer,section,aside,nav,article等,這裡我們截圖看一個整體佈局

唯一的H1標題
每個頁面都應該有一個唯一的h1標題,但不是每個頁面的h1標題都是網站名稱。 (但html5中h1標題是可以多次出現的,每個具有結構大綱的標籤都可以擁有自己獨立的h1標題,如header,footer,section,aside,article)
首頁的h1標題為網站名稱,內頁的h1標題為各個內頁的標題,如分類頁用分類的名字,詳細頁以詳細頁標題作為h1標題
<!-- 首頁 -->
<h1 class="page-tt">騰訊課堂</h1>
<!-- 分類頁 -->
<h1 class="page-tt">前端開發線上培訓影片教學</h1>
<!-- 詳細頁 -->
<h1 class="page-tt">html5+CSS3</h1>img設定alt屬性
img必須設定alt屬性,如果寬度和高度固定請同時設定固定的值
<img src="" alt="seo优化实战" width="200" height="100" />nofollow
對不需要跟踪爬行的鏈接,設置nofollow。可用在部落格評論、論壇貼文、社會化網站、留言板等地方,也可用於廣告鏈接,還可用於隱私政策,用戶條款,登入等。如下程式碼表示該連結不需要追蹤爬行,可以阻止蜘蛛爬行及傳遞權重。
<a href="http://example.com" rel="nofollow">no follow 鏈接</a>正文
內容方面考慮:
- 自然寫作
- 高品質原創內容
- 吸引閱讀的寫作手法
- 突顯賣點
- 增強信任感
- 引導進一步行為
使用者體驗方面考量:
- 排版合理、清晰、美觀、字體、背景易於閱讀
- 實質內容處在頁面最重要位置,使用者一眼就能看到
- 實質內容與廣告能清楚區分
- 第一屏就有實質內容,而不是需要下拉頁面才能看到
- 廣告數量不宜過多,位置不應該妨礙用戶閱讀
- 如果圖片、影片有利於使用者理解頁面內容,盡量製作圖片、影片等
- 避免過多彈窗
URL優化
URL設計原則:
- 越短越好
- 避免太多參數
- 目錄層次盡量少
- 文件及目錄名具描述性
- URL中包含關鍵字(中文除外)
- 字母全部小寫
- 連接詞符使用
-而不是_ - 目錄形式而非文件形式
URL靜態化
以現在搜尋引擎的爬行能力是可以不用做靜態化的,但是從收錄難易度,用戶體驗及社會化分享,靜態簡短的URL都是更有利的。
URL靜態化還是不靜態化?
資料庫驅動的網站需要將URL靜態化,一直以來都是SEO最基本的要求,可以算是個常識性的東西。現在恐怕也沒有不是資料庫驅動的網站了吧。
近幾年SEO產業一致認為,URL中帶2-3個問號不是問題,搜尋引擎通常都能收錄,尤其是權重高點的域名,更多幾個問號也不是問題。但無論如何一般還是建議URL靜態化。
2008年9月份,Google站長部落格發表了一篇討論動態網址還是靜態網址的帖子,卻顛覆了這個說法。在這篇貼文裡,Google明確建議不要將動態URL靜態化,而是保留那種長長的,帶問號參數的動態URL。 Google黑板報和中文網站管理員部落格都做了翻譯和轉載,大家可以查看。
從留言和我看到的部落格來看,有不少人還真覺得有道理,準備照Google說的做了。
這是比較少見的,我十分不以為然的,Google給的SEO建議。
Google的貼文有幾個要點。
一是Google完全有能力抓取動態網址,多少個問號也不是問題。這一點基本可靠。但如果URL中出現個十幾二十個問號和參數呢? Google會怎麼看待?即使有能力抓取,一定會願意抓取嗎?其它搜尋引擎又會怎樣處理?
第二,動態網址更有助於Google蜘蛛讀懂URL意義,並進行鑑別,因為網址中的參數有提示性。例如Google舉了這個例子:
http://www.example.com/article/bin/answer.foo?language=en&answer=3&sid=98971298178906&query=URL
URL裡的參數都有助於Google理解URL及網頁內容。例如language後面跟的參數是提示語言,answer後面跟的是文章編號,sid後面的一定是session ID。其他常用的包括color後面接的參數指的是顏色,size後面接的參數是尺寸等。有了這些參數的幫助,Google更容易理解網頁。
而將網址靜態化後,這些參數的意義通常就變得不明顯了。例如這個URL:
http://www.example.com/shoes/red/7/12/men/index.html
就可能使Google不知道哪個是產品序號,哪個是尺寸等。
第三,網址靜態化很容易弄錯,那就更得不償失了。例如通常動態網址的參數調換順序,得到的頁面其實是相同的,例如這兩個網址很可能就是同一個頁面:
http://www.example.com/article/bin/answer.foo?language=en&answer=3
http://www.example.com/article/bin/answer.foo?answer=3&language=en
保留動態網址,Google還比較容易明白這是一樣的網頁。而經過靜態化後,這樣兩個網址Google就不容易判斷是不是同一個頁面,從而可能引起複製內容:
http://www.example.com/shoes/men/7/red/index.html
http://www.example.com/shoes/red/7/men/index.html
再一個容易搞錯的是session ID,也可能被靜態化進URL:
http://www.example.com/article/bin/answer.foo/en/3/98971298178906/URL
這樣網站將產生大量URL不同,但其實內容相同的頁面。
所以,Google建議不要靜態化URL。
但我還是建議要靜態化。原因是:
首先,Google給的建議是從Google自己出發,而沒有考慮其他搜尋引擎。 Google抓取動態網址沒問題,不代表雅虎,百度,微軟等等都沒問題。尤其是中文網站,Google不是老大。實際上,百度直到現在,2021年,對多個問號的URL還是不太願意抓取的。
第二,Google所說靜態化的壞處,是基於靜態化做得不正確的假設上。問題是要做靜態化就得做正確,假設會做錯是沒有什麼道理的。有幾個人會靜態化網址時還把session ID放進去呢?
第三,Google的建議是典型的有利於自己,不利於使用者。帶有問號參數的URL可能有助於Google讀懂內容,但是顯然非常不利於使用者在一撇之下理解網站結構及大致內容。看看這兩個網址哪個比較清晰,比較容易讀懂,更有可能被點擊呢?
http://www.example.com/product/men/shoes/index.html
顯然是第二個。
而且長的動態網址,也不利於記憶,不利於在郵件、社會化網站等地方抄給別人。
總之,雖然Google這麼明確的建議保留動態網址,我還是建議正相反,盡量將URL靜態化。
URL規範化
1、統一連接
http://www.domainname.com
http://domainname.com
http://www.domainname.com/index.html
http://domainname.com/index.html以上四個其實都是首頁,雖然不會給訪客造成什麼麻煩,但對於搜尋引擎來說就是四條網址,並且內容相同,很可能會被誤認為是作弊手段,而且當搜尋引擎要規範化網址時,需要從這些選擇當中挑一個最好的代表,但是挑的這個不一定是你想要的。所以最好自己就規範好。
2、301跳轉
第一種是URL改變,一定要把舊的地址301指向新的,不然之前做的一些收錄權重什麼的全白搭了。
第二種是一些cms系統,極有可能會造成多個路徑對應同一篇文章。如drupal預設的路徑是以node/nid,但如果啟用了path token,就可以自己自訂路徑。這樣一來就有兩條路徑對應同一篇文章。所以可以啟用301,最終轉向一條路徑。
3、canonical
這個標籤表示頁面的唯一性(這個標籤以前百度不支持,現在支持),用在平時參數傳遞的時候,如:
//:ke.qq.com/download/app.html
//:ke.qq.com/download/app.html?from=123
//:ke.qq.com/download/app.html?from=456以上三個表示三個頁面,但其實後兩個只是想表明從哪裡來的而已,所以為了確保這三個是同一個頁面,我們在head上加上canonical標籤。
<link rel="cononical" href="//:ke.qq.com/download/download/app.html" />robots
robots.txt
搜尋引擎蜘蛛訪問網站時會第一個訪問robots.txt文件,robots.txt用於指導搜尋引擎蜘蛛禁止抓取網站某些內容或只允許抓取那些內容,放在網站根目錄。
以騰訊課堂的robots.txt為例:

- User-agent 表示下列規則適用哪一個蜘蛛,
*表示所有 #表示註釋- Disallow 表示禁止抓取的檔案或目錄,必須每個一行,分開寫
- Allow 表示允許抓取的檔案或目錄,必須每個一行,分開寫
- Sitemap 表示網站XML地圖,注意S大寫
以下表示禁止所有搜尋引擎蜘蛛抓取任何內容
User-agent: *
Disallow: /以下表示允許所有搜尋引擎蜘蛛抓取任何內容
User-agent: *
Disallow:注意:被robots禁止抓取的URL還是肯呢個被索引並出現在搜尋結果中的。只要有導入連結指向這個URL,搜尋引擎就知道這個URL的存在,雖然不會抓取頁面內容,但是索引庫還是有這個URL的資訊。以淘寶為例:
禁止百度搜尋引擎抓取

百度搜尋有顯示

如何使用robots.txt及其詳解
在國內,網站管理者似乎對robots.txt並沒有引起多大重視,應一些朋友之請求,今天想透過這篇文章來簡單談一下robots.txt的寫作。
robots.txt基本介紹
robots.txt是一個純文字文件,在這個文件中網站管理者可以聲明該網站中不想被robots訪問的部分,或者指定搜尋引擎只收錄指定的內容。
當一個搜尋機器人(有的叫搜尋蜘蛛)造訪一個網站時,它會先檢查該網站根目錄下是否存在robots.txt,如果存在,搜尋機器人就會按照該檔案中的內容來確定存取的範圍;如果該檔案不存在,那麼搜尋機器人就沿著連結抓取。
另外,robots.txt必須放置在一個網站的根目錄下,而且檔案名稱必須全部小寫。
robots.txt寫作文法
首先,我們來看一個robots.txt範例:https://www.example.com/robots.txt
造訪以上具體地址,我們可以看到robots.txt的具體內容如下:
# Robots.txt file from https://www.example.com
# All robots will spider the domain
User-agent: *
Disallow:
以上文字表達的意思是允許所有的搜尋機器人存取https://uzbox.com網站下的所有文件。
具體語法分析:其中#後面文字為說明訊息;User-agent:後面為搜尋機器人的名稱,後面如果是*,則泛指所有的搜尋機器人;Disallow:後面為不允許存取的檔案目錄。
下面,我將列舉一些robots.txt的具體用法:
允許所有的robot訪問
User-agent: *
Disallow:
或者也可以建立一個空檔案"/robots.txt" file
禁止所有搜尋引擎造訪網站的任何部分
User-agent: *
Disallow: /
禁止所有搜尋引擎造訪網站的幾個部分(下例中的01、02、03目錄)
User-agent: *
Disallow: /01/
Disallow: /02/
Disallow: /03/
禁止某個搜尋引擎的存取(下例中的BadBot)
User-agent: BadBot
Disallow: /
只允許某個搜尋引擎的存取(下例中的Crawler)
User-agent: Crawler
Disallow:
User-agent: *
Disallow: /
另外,我覺得有必要進行拓展說明,對robots meta做一些介紹:
Robots META標籤則主要是針對一個個特定的頁面。和其他的META標籤(如使用的語言、頁面的描述、關鍵字等)一樣,Robots META標籤也是放在頁面的<head></head>中,專門用來告訴搜尋引擎ROBOTS如何抓取該頁的內容。
Robots META標籤的寫法:
Robots META標籤中沒有大小寫之分,name=”Robots」表示所有的搜尋引擎,可以針對某個特定搜尋引擎寫為name=”BaiduSpider」。 content部分有四個指令選項:index、noindex、follow、nofollow,指令間以「,」分隔。
INDEX 指令告訴搜尋機器人抓取該頁面;
FOLLOW 指令表示搜尋機器人可以沿著該頁面上的連結繼續抓取下去;
Robots Meta標籤的預設值是INDEX和FOLLOW,只有inktomi除外,對於它,缺省值是INDEX,NOFOLLOW。
這樣,一共有四種組合:
<META NAME="ROBOTS" CONTENT="INDEX,FOLLOW">
<META NAME="ROBOTS" CONTENT="NOINDEX,FOLLOW">
<META NAME="ROBOTS" CONTENT="INDEX,NOFOLLOW">
<META NAME="ROBOTS" CONTENT="NOINDEX,NOFOLLOW">
其中
<META NAME="ROBOTS" CONTENT="INDEX,FOLLOW">可以寫成<META NAME="ROBOTS" CONTENT="ALL">;
<META NAME="ROBOTS" CONTENT="NOINDEX,NOFOLLOW">可寫成<META NAME="ROBOTS" CONTENT="NONE">
目前看來,絕大多數的搜尋引擎機器人都遵守robots.txt的規則,而對於Robots META標籤,目前支援的並不多,但是正在逐漸增加,如著名搜尋引擎GOOGLE就完全支持,而且GOOGLE還增加了一個指令“archive”,可以限制GOOGLE是否保留網頁快照。例如:
<META NAME="googlebot" CONTENT="index,follow,noarchive">
表示抓取該網站中頁面並沿著頁面中連結抓取,但是不在GOOLGE上保留該頁面的網頁快照。
如何使用robots.txt
robots.txt 檔案對抓取網路的搜尋引擎漫遊器(稱為漫遊車)進行限制。這些漫遊器是自動的,在它們訪問網頁前會查看是否存在限制其訪問特定網頁的robots.txt 檔案。如果你想保護網站上的某些內容不被搜尋引擎收入的話,robots.txt是一個簡單有效的工具。這裡簡單介紹一下怎麼使用它。
如何放置Robots.txt文件
robots.txt本身是一個文字檔。它必須位於網域的根目錄中並被命名為"robots.txt"。位於子目錄中的robots.txt 檔案無效,因為漫遊器只在網域的根目錄中尋找此檔案。例如,http://www.example.com/robots.txt 是有效位置,http://www.example.com/mysite/robots.txt 則不是。
這裡舉一個robots.txt的例子:
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /~name/
使用robots.txt 檔案攔截或刪除整個網站
若要從搜尋引擎中刪除您的網站,並防止所有漫遊器在以後抓取您的網站,請將以下robots.txt 檔案放入您伺服器的根目錄:
User-agent: *
Disallow: /
要只從Google 中刪除您的網站,並只是防止Googlebot 將來抓取您的網站,請將以下robots.txt 檔案放入您伺服器的根目錄:
User-agent: Googlebot
Disallow: /
每個連接埠都應有自己的robots.txt 檔案。尤其是您透過http 和https 託管內容的時候,這些協議都需要有各自的robots.txt 檔案。例如,要讓Googlebot 只為所有的http 網頁而不為https 網頁編制索引,應使用下面的robots.txt 檔案。
對於http 協定 (http://www.example.com/robots.txt):
User-agent: *
Allow: /
對於https 協議 (https://www.example.com/robots.txt):
User-agent: *
Disallow: /
允許所有的漫遊器造訪您的網頁
User-agent: *
Disallow:
(另一種方法: 建立一個空的"/robots.txt" 檔案, 或不使用robot.txt。)
使用robots.txt 檔案攔截或刪除網頁
您可以使用robots.txt 檔案來阻止Googlebot 抓取您網站上的網頁。 例如,如果您正在手動建立robots.txt 檔案以阻止Googlebot 抓取某一特定目錄下(例如,private)的所有網頁,可使用下列robots.txt 項目:
User-agent: Googlebot
Disallow: /private
若要阻止Googlebot 抓取特定文件類型(例如,.gif)的所有文件,可使用以下robots.txt 條目:
User-agent: Googlebot
Disallow: /*.gif$
要阻止Googlebot 抓取所有包含? 的網址(具體地說,這種網址以您的域名開頭,後接任意字符串,然後是問號,而後又是任意字符串),可使用以下條目:
User-agent: Googlebot
Disallow: /*?
儘管我們不抓取被robots.txt 攔截的網頁內容或為其編制索引,但如果我們在網路上的其他網頁中發現這些內容,我們仍然會抓取其網址並編制索引。因此,網頁網址及其他公開的訊息,例如指向該網站的連結中的定位文字,有可能會出現在Google 搜尋結果中。不過,您網頁上的內容不會被抓取、編製索引和顯示。
作為網站管理員工具的一部分,Google提供了robots.txt分析工具。它可以按照Googlebot 讀取robots.txt 檔案的相同方式讀取該文件,並且可為Google user-agents(如Googlebot)提供結果。我們強烈建議您使用它。 在建立robots.txt檔案之前,有必要考慮哪些內容可以被使用者搜尋得到,而哪些則不應該被搜尋。 這樣的話,透過合理地使用robots.txt, 搜尋引擎在把使用者帶到您網站的同時,又能確保隱私資訊不被收錄。
迷思一:我的網站上的所有檔案都需要蜘蛛抓取,那我就沒必要在新增robots.txt檔案了。反正如果該檔案不存在,所有的搜尋蜘蛛將預設能夠存取網站上所有沒有被口令保護的頁面。
每當使用者試圖存取某個不存在的URL時,伺服器都會在日誌中記錄404錯誤(無法找到檔案)。每當搜尋蜘蛛來尋找不存在的robots.txt檔案時,伺服器也會在日誌中記錄一條404錯誤,所以你應該做網站中新增一個robots.txt。
迷思二:在robots.txt檔案中設定所有的檔案都可以被搜尋蜘蛛抓取,這樣可以增加網站的收錄率。
網站中的程式腳本、樣式表等檔案即使被蜘蛛收錄,也不會增加網站的收錄率,只會浪費伺服器資源。因此必須在robots.txt檔案中設定不要讓搜尋蜘蛛索引這些檔案。
具體哪些文件需要排除, 在robots.txt使用技巧一文中有詳細介紹。
迷思三:搜尋蜘蛛抓取網頁太浪費伺服器資源,在robots.txt檔案設定所有的搜尋蜘蛛都不能抓取全部的網頁。
如果這樣的話,會導致整個網站不能被搜尋引擎收錄。
robots.txt使用技巧
1. 每當使用者試圖存取某個不存在的URL時,伺服器都會在日誌中記錄404錯誤(無法找到檔案)。每當搜尋蜘蛛來尋找不存在的robots.txt檔案時,伺服器也會在日誌中記錄一個404錯誤,所以你應該在網站中新增一個robots.txt。
2. 網站管理員必須使蜘蛛程式遠離某些伺服器上的目錄-保證伺服器效能。例如:大多數網站伺服器都有程式儲存在「cgi-bin」目錄下,因此在robots.txt檔案中加入「Disallow: /cgi-bin」是個好主意,這樣能夠避免將所有程式檔案被蜘蛛索引,可以節省伺服器資源。一般網站中不需要蜘蛛抓取的文件有:後台管理文件、程式腳本、附件、資料庫文件、編碼文件、樣式表文件、範本文件、導覽圖片和背景圖片等等。
下面是VeryCMS裡的robots.txt檔案:
User-agent: *
Disallow: /admin/ 後台管理文件
Disallow: /require/ 程式文件
Disallow: /attachment/ 附件
Disallow: /images/ 圖片
Disallow: /data/ 資料庫文件
Disallow: /template/ 模板文件
Disallow: /css/ 樣式表文件
Disallow: /lang/ 編碼文件
Disallow: /script/ 腳本文件
3. 如果你的網站是動態網頁,並且你為這些動態網頁創建了靜態副本,以供搜尋蜘蛛更容易抓取。那你需要在robots.txt檔案中設定避免動態網頁被蜘蛛索引,以確保這些網頁不會被視為含重複內容。
4. robots.txt檔案裡還可以直接包含在sitemap檔案的連結。就像這樣:
Sitemap: sitemap.xml
目前對此表示支持的搜尋引擎公司有Google, Yahoo, Ask and MSN。而中文搜尋引擎公司,顯然不在這個圈子內。這樣做的好處就是,站長不用到每個搜尋引擎的站長工具或相似的站長部分,去提交自己的sitemap文件,搜尋引擎的蜘蛛自己就會抓取robots.txt文件,讀取其中的sitemap路徑,接著抓取其中相連結的網頁。
5. 合理使用robots.txt檔案還能避免存取時發生錯誤。例如,不能讓搜尋者直接進入購物車頁面。因為沒有理由讓購物車被收錄,所以你可以在robots.txt檔案裡設定來阻止搜尋者直接進入購物車頁面。
meta robots
如果要想URL完全不出現在搜尋結果中,則需設定meta robots
<meta name="robots" content="onindex,nofollow">上面程式碼表示:禁止所有搜尋引擎索引本頁,禁止追蹤本頁上的連結。
當然還有其他類型的content,不過各個瀏覽器支援情況不同,所以這裡忽略。
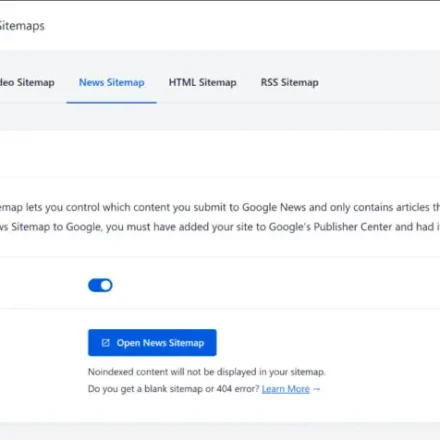
sitemap
網站地圖格式分為HTML和XML兩種。
HTML版本的是普通的HTML頁面sitemap.html,用戶可以直接訪問,可以列出網站的所有主要鏈接,建議不超過100條。
XML版本的網站地圖是google在2005年提出的,由XML標籤組成,編碼為utf-8,羅列頁面所有的URL。其格式如下:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>//ke.qq.com
<lastmod>2015-12-28</lastmod>
<changefreq>always</changefreq>
<priority>1.0</priority>
</url>
...
</urlset>其中urlset,url,loc三個為必須標籤,lastmod,changefreq,priority為可選標籤。
lastmod表示頁面最後一次更新時間。
changefreq表示文件更新頻率,有以下幾種取值:always, hourly, daily, weekly, monthly, yearly, never。其中always表示一直變動,每次造訪頁面內容都不同;而never表示從來不變。
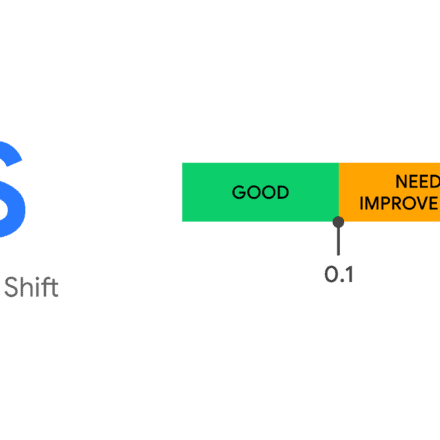
priority表示URL相對重要程度,取值範圍為0.0-1.0,1.0表示最重要,一般用在網站首頁,對應的0.0就是最不重要的,預設重要程度為0.5。 (注意這裡的重要度是我們標記的,不代表搜尋引擎真的就完全按照我們設定的重要性來排列)
sitemap.xml不能超過10M,而且每個sitemap檔案中url的條數不要超過5萬條,當你的sitemap檔案很大的時候,可以分解為多個檔案。如下分為兩條,一條為基礎,一條為產品詳細頁。
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap><loc>//ke.qq.com/sitemap-basic.xml2015-12-28T02:10Z
<sitemap><loc>//ke.qq.com/sitemap-product.xml2015-12-28T02:10Z
</sitemapindex>SEO工具
- 百度搜尋風雲榜
- 百度指數
- 百度站長平台
- meta seo inspector,檢查標籤的,Google插件
- seo in china,百度收錄的各種數據,Google插件
- check my links,檢查鏈接,谷歌插件
- seo quake,統計各種數據,Google插件
最後,本文參考百度搜尋引擎優化指南2.0 和zac著作《SEO實戰密碼》(對SEO有興趣的同學,可以買本看看)。