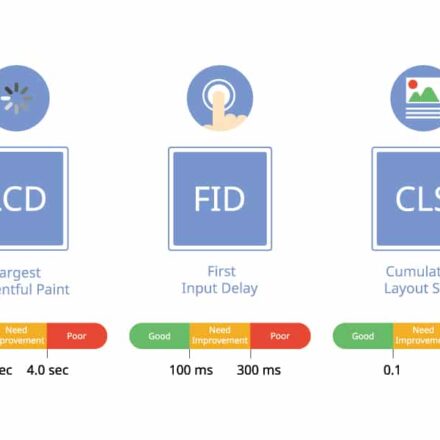
優れたソフトウェアと実用的なチュートリアル




robots メタタグとは何ですか?
有効活用するロボットメタタグロボットSEOの効果を高め、ウェブサイトの最適化とGoogle検索結果への表示に必須です。robotsメタタグは、ページレベルの設定で、ウェブページをインデックスに登録して検索結果に表示するかどうかを制御します。robotsメタタグは、検索エンジンに何をフォローし、何をフォローしないかを指示するタグです。
robots メタタグはどこに配置すればよいですか?
robots メタタグは Web ページのヘッダーセクションに配置されます。
robotsメタタグの書き方
このタグは、すべての検索エンジンにこのページをインデックスしないように指示し、検索結果に表示されないようにします。

data-nosnippet と X-Robots-Tag の記述を標準化する
ページレベルとテキストレベルの設定を使用して、Googleの検索結果におけるコンテンツの表示方法を調整する方法。ページレベルの設定は、HTMLページまたはHTTPヘッダーにメタタグを追加することで指定できます。 データなしスニペット テキスト レベルの設定を指定するプロパティ。
これらの設定は、クローラーがそれらの設定を含むページにアクセスできる場合にのみ読み取られ、尊重されることに注意してください。
タグまたはディレクティブは検索エンジンのクローラに適用されます。検索エンジン以外のクローラ(AdsBot-Googleなど)をブロックしたい場合は、特定のクローラ用のディレクティブを追加する必要があるかもしれません。例:
robotsメタタグの使用
robots メタタグを使用すると、ページレベルの詳細な設定を使用して、個々のページがどのようにインデックスに登録され、Google 検索結果に表示されるかを制御できます。robots メタタグは、特定のページのヘッダーセクションに配置します。
この例では、robots メタタグは検索エンジンにページを検索結果に表示しないよう指示しています。name 属性の値 (robots) は、このディレクティブがすべてのクローラに適用されることを示しています。特定のクローラをターゲットにするには、name 属性の robots 値をそのクローラの名前に置き換えます。特定のクローラはユーザーエージェントとも呼ばれます (クローラはユーザーエージェントを使用してページをリクエストします)。Google の標準ウェブクローラのユーザーエージェント名は Googlebot です。Googlebot によるページのインデックス作成のみを禁止したい場合は、タグを次のように更新します。
このタグにより、Google 検索結果にこのページを表示しないように Google に明示的に指示できるようになります。name 属性と content 属性はどちらも大文字と小文字を区別しません。
検索エンジンは、目的に応じて異なるクローラーを使用する場合があります。詳細については、 Googleクローラーの完全なリストたとえば、ページを Google のウェブ検索結果には表示したいが、Google ニュースには表示したくない場合は、次のメタタグを使用できます。
複数のクローラーを個別に指定するには、複数の robots メタタグを使用します。
HTML以外のリソース(PDFファイル、ビデオファイル、画像ファイルなど)がインデックスに登録されないようにするには、 X-Robots-タグ レスポンス ヘッダー。
X-Robots-Tag HTTPヘッダーの使用
X-Robotsタグは、特定のURLのHTTPヘッダーレスポンスの要素として使用できます。robotsメタタグで使用できるディレクティブはすべて、X-Robotsタグとして指定できます。以下は、クローラーにページをインデックスしないよう指示するX-Robotsタグを含むHTTPレスポンスの例です。
HTTP/1.1 200 OK 日付: 2010年5月25日(火) 21:42:43 GMT (…) X-Robots-Tag: noindex (…)
HTTPレスポンスでは複数のX-Robots-Tagヘッダーを組み合わせたり、カンマ区切りのディレクティブリストを指定したりできます。次のHTTPレスポンスヘッダーの例では、noarchive X-Robots-Tagとunavailable_after X-Robots-Tagを組み合わせています。
HTTP/1.1 200 OK 日付: 2010年5月25日(火) 21:42:43 GMT (…) X-Robots-Tag: noarchive X-Robots-Tag: unavailable_after: 2010年6月25日(日) 15:00:00 PST (…)
X-Robots-Tag では、ディレクティブの前にユーザーエージェントを指定することもできます。例えば、以下の X-Robots-Tag HTTP ヘッダーセットを使用すると、条件に応じてページを異なる検索エンジンの検索結果に表示させることができます。
HTTP/1.1 200 OK 日付: 2010年5月25日(火) 21:42:43 GMT (…) X-Robots-Tag: googlebot: nofollow X-Robots-Tag: otherbot: noindex, nofollow (…)
ディレクティブでユーザーエージェントが指定されていない場合、すべてのクローラーに適用されます。HTTPヘッダー、ユーザーエージェント名、および指定された値は大文字と小文字が区別されません。
競合するロボットディレクティブ:競合するロボットディレクティブが存在する場合、より制限の厳しいディレクティブが優先されます。例えば、ページに max-snippet:50 と nosnippet ディレクティブの両方が含まれている場合、 nosnippet ディレクティブが優先されます。
有効なインデックス作成とコンテンツ配信の指示
以下のディレクティブをrobotsメタタグとX-Robotsタグと組み合わせて使用することで、インデックス登録とスニペットの表示を制御できます。検索結果におけるスニペットとは、ユーザーのクエリに対するドキュメントの関連性を示す短いテキストの抜粋です。以下の表は、Googleがサポートするすべてのディレクティブとそれぞれの意味を示しています。各値は特定のディレクティブを表します。複数のディレクティブを組み合わせることもできます。カンマ区切りのリストにまとめるか、複数のメタタグを使用するこれらの手順では大文字と小文字は区別されません。



インデックス作成と配信指示の組み合わせを処理する方法
複数のrobotsメタタグディレクティブをカンマで区切って組み合わせたり、複数のメタタグを使って複数のディレクティブを含む単一のコマンドを作成したりできます。以下は、ウェブクローラーにページをインデックスせず、ページ上のリンクをクロールしないように指示するrobotsメタタグの例です。
カンマ区切りリスト
複数のメタタグ
次の例では、テキスト抜粋の長さを 20 文字に制限し、大きな画像プレビューを許可します。
複数のクローラを指定し、各クローラに異なるディレクティブが設定されている場合、検索エンジンはすべての除外ディレクティブをまとめて使用します。例:
Googlebot はこれらのメタタグを含むページをクロールすると、それらのページを noindex、nofollow ディレクティブがあるものとして扱います。
data-nosnippet HTML属性の使用
HTMLページのどのテキスト部分をスニペットの生成に使用しないかを指定できます。これは、HTML要素レベルで、span、div、section要素のdata-nosnippet HTML属性を使用して行うことができます。data-nosnippetはブール属性として扱われます。他のブール属性と同様に、指定された値は無視されます。機械可読性を確保するには、HTMLセクションが有効なHTMLであり、すべてのタグに対応する終了タグが必要です。
Google は通常、ページをインデックス登録するためにレンダリングしますが、レンダリングが保証されるわけではありません。そのため、レンダリングの前後両方で data-nosnippet が抽出される可能性があります。レンダリングの不確実性を回避するには、JavaScript を使用して既存のノードに data-nosnippet 属性を追加または削除しないでください。JavaScript を使用して DOM 要素を追加する場合は、ページの DOM に要素を最初に追加するときに、必要に応じて data-nosnippet 属性を含めてください。カスタム要素を使用しており、data-nosnippet を使用する必要がある場合は、div 要素、span 要素、または section 要素で囲むかレンダリングしてください。
構造化データを使用する
robots メタタグは、Google がページから自動的に抽出して検索結果として表示するコンテンツの量を制御します。ただし、多くのサイト運営者は、検索表示用の特定の情報を提供するために schema.org 構造化データも使用しています。robots メタタグの制限は、他のクリエイティブ作品に指定される構造化データの article.description 値と description 値を除き、その構造化データの使用には影響しません。これらの description 値に基づいてプレビューの最大長を指定するには、max-snippet robots メタタグを使用します。たとえば、テキストプレビューが制限されている場合でも、ページ上のレシピ構造化データはレシピカルーセルに含めることができます。max-snippet を使用してテキストプレビューの長さを制限できますが、構造化データを使用してリッチリザルトの情報を提供する場合は、この robots メタタグは使用されません。
ページ上での構造化データの使用方法を管理するには、構造化データのタイプと値自体を編集し、必要なデータのみが利用できるようにします。また、data-nosnippet 要素内で宣言されている構造化データは、検索結果の表示にも使用できます。
実際にX-Robots-Tagを追加する
ウェブサイトのウェブサーバーソフトウェアの設定ファイルを通じて、ウェブサイトのHTTPレスポンスにX-Robots-Tagsを追加できます。例えば、Apacheベースのウェブサーバーでは、.htaccessファイルとhttpd.confファイルを使用できます。HTTPレスポンスでX-Robots-Tagsを使用する利点は、ウェブサイト全体に適用されるクロール指示を指定できることです。正規表現がサポートされているため、非常に柔軟な設定が可能です。
たとえば、サイト全体のすべての .PDF ファイルに対する HTTP 応答に noindex、nofollow X-Robots-Tag を追加するには、Apache サイトの場合はルート .htaccess または httpd.conf ファイル、NGINX サイトの場合は .conf ファイルに次のスニペットを追加します。
アパッチ
ヘッダーにX-Robots-Tag「noindex、nofollow」を設定
NGINX
場所 ~* \.pdf$ { add_header X-Robots-Tag "noindex, nofollow"; }
HTMLのrobotsメタタグを使用できない非HTMLファイル(画像ファイルなど)の場合は、X-Robots-Tagを使用できます。以下の例は、サイト全体の画像ファイル(.png、.jpeg、.jpg、.gif)にnoindex X-Robots-Tagディレクティブを追加する方法を示しています。
アパッチ
ヘッダーにX-Robots-Tagを「noindex」に設定
NGINX
場所 ~* \.(png|jpe?g|gif)$ { add_header X-Robots-Tag "noindex"; }
個々の静的ファイルに対して X-Robots-Tag ヘッダーを設定することもできます。
アパッチ
# htaccess ファイルは、一致したファイルのディレクトリに配置する必要があります。ヘッダーにX-Robots-Tag「noindex、nofollow」を設定
NGINX
location = /secrets/unicorn.pdf { add_header X-Robots-Tag "noindex, nofollow"; }
robots.txt の指示とインデックスおよびコンテンツ配信の指示を組み合わせる
robotsメタタグとX-Robots-Tag HTTPヘッダーは、URLがクロールされた場合にのみクローラーに表示されます。robots.txtファイルでページをブロックした場合、クローラーはインデックス作成/配信ディレクティブに関する情報を取得できず、無視します。インデックス作成/配信ディレクティブに従う必要がある場合、これらのディレクティブを含むURLのクロールをクローラーがブロックすることはできません。
元のリンク:https://developers.google.com/search/docs/advanced/robots/robots_meta_tag?hl=zh-cn